

Run.AI raises $13M for its distributed machine learning platform
Tel Aviv’s Run.AI, a startup that is building a new virtualization and acceleration platform for deep learning, is coming out of stealth today. As a part of this announcement, the company also announced that it has now raised a total of $13 million. This includes a $3 million seed round from TLV Partners and a $10 million Series A round led by Haim Sadger’s S Capital and TLV Partners.
It’s no secret that building deep learning models take a hefty amount of GPU power or access to specialized AI chips. Run.AI argues that the virtualization layers that worked so well for in the past don’t quite cut it for training today’s AI models.
“We believe that we’re only scratching the surface of the full potential of deep learning,” Run.AI CEO and co-founder Omri Geller told me. “But the computational infrastructure needs of deep learning are a totally different ballgame. […] The rise of deep learning is triggering a new era of compute.”
Traditionally, Geller argues, virtualization was all about being generous and sharing the resources of a single machine for workloads that typically only run for a short time or use a small amount of resources. Deep learning workloads, however, are very different and are essentially selfish in that they want to take over all the available compute resources of a given machine. These training sessions also typically run for hours or days. At its core, what Run.AI offers is a new virtualization layer for distributed machine learning tasks that can across a large number of machines.
“We built a compute abstraction layer that bridges the gap between the new form of workloads and the new hardware that is evolving,” said Geller. “By using this abstraction layer, we can achieve 100x faster compute using distributed computing. We can double the resource utilization of the hardware and we can bring to companies the control over time and cost regarding deep learning.” That’s 100x faster than using a single resource, though that’s a bit aspirational as Geller also tells me that the team is seeing about a 10x speedup in production right now, though he’s confident that the team will get to 100x over time. Either way, though, the promise here is that the service will allow you to optimize the utilization of your deep learning workloads.
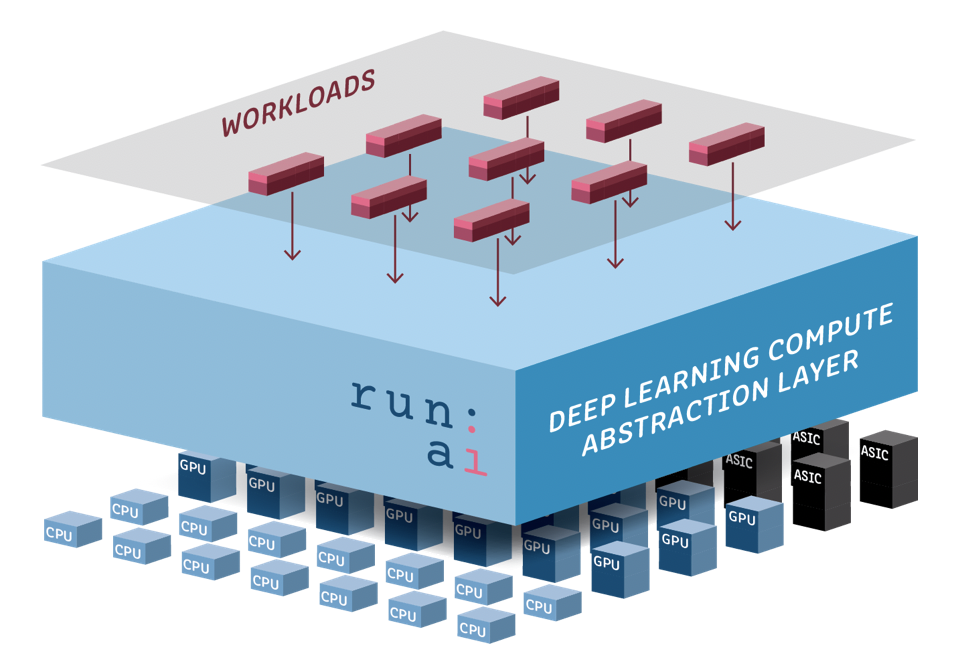
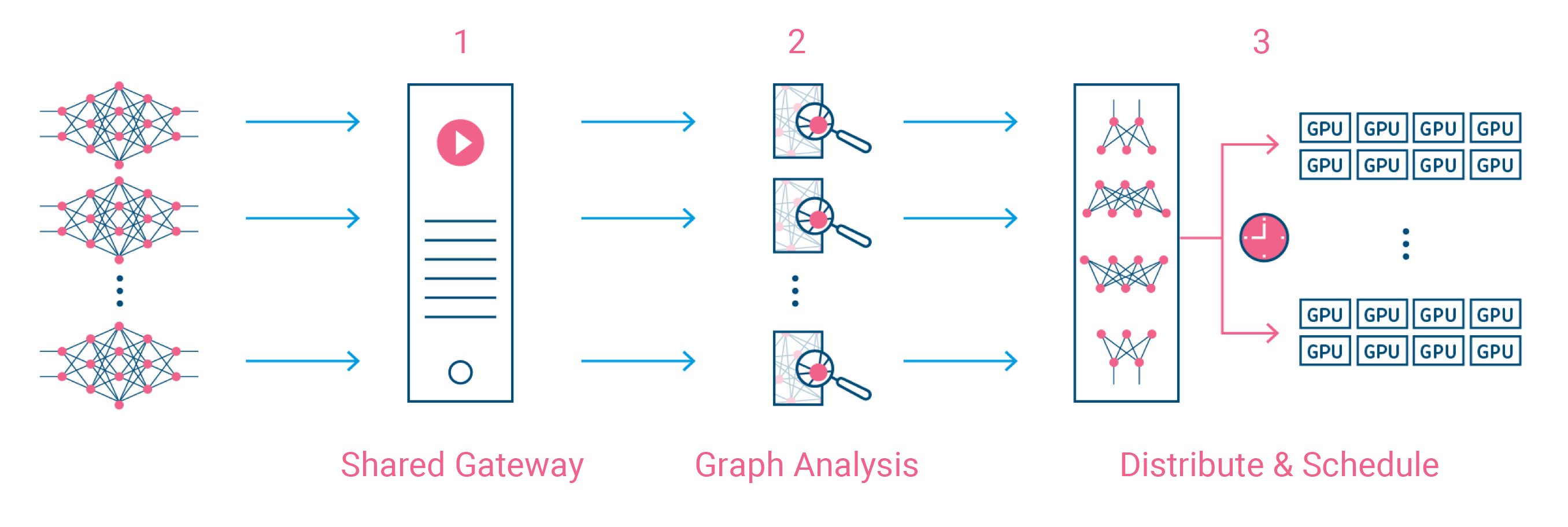
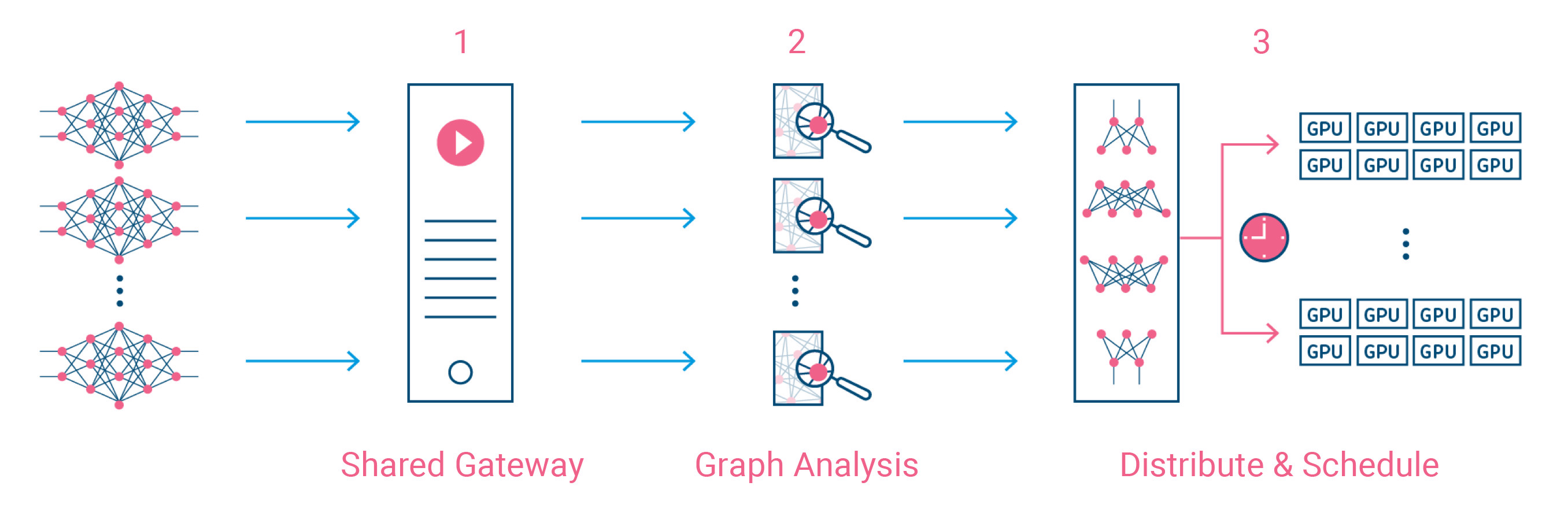
That’s only one part of the company’s solution, though. In addition, the company’s tools also analyze the model in order to break it down into smaller models that can then run in parallel across these servers. With that, the service can understand how many resources a workload would need and what machines to best send the given workloads to. In doing this, the system takes into account everything from available compute resources to network bandwidth, as well as the data pipeline and size.
The company also argues that this allows it to train large models that are bigger than the individual GPU memory capacity of a single machine.
There’s a financial aspect to this, too, because users can determine whether they want the service to prioritize cost savings over training speed, for example. The platform supports both private and public cloud deployments. In private clouds, cost savings are obviously less of a factor but the premise of increased utlization of the existing hardware investment will likely be a draw for many of these users.
The company, which was founded by Geller, Dr. Ronen Dar and Prof. Meir Feder, was founded in 2018. While still in stealth, it signed a number of early customers and opened a U.S. office.


{kind=link}